2025年12月26日,由哈尔滨工业大学(深圳)高翠芸教授主办的第十四期硕博论坛——“大模型数据治理与高效训练”在哈尔滨工业大学(深圳)信息楼L-316顺利召开。本期论坛以“大模型数据治理与高效训练”为主题,邀请南京大学博士研究生肖媛、香港科技大学(广州)博士研究生尹一鸣作专题报告,分享了他们在代码大模型数据治理与多模态大模型高效训练的最新研究成果。论坛采用线下形式,现场学术氛围浓厚,互动热烈,取得良好交流成效。
肖媛同学进行分享
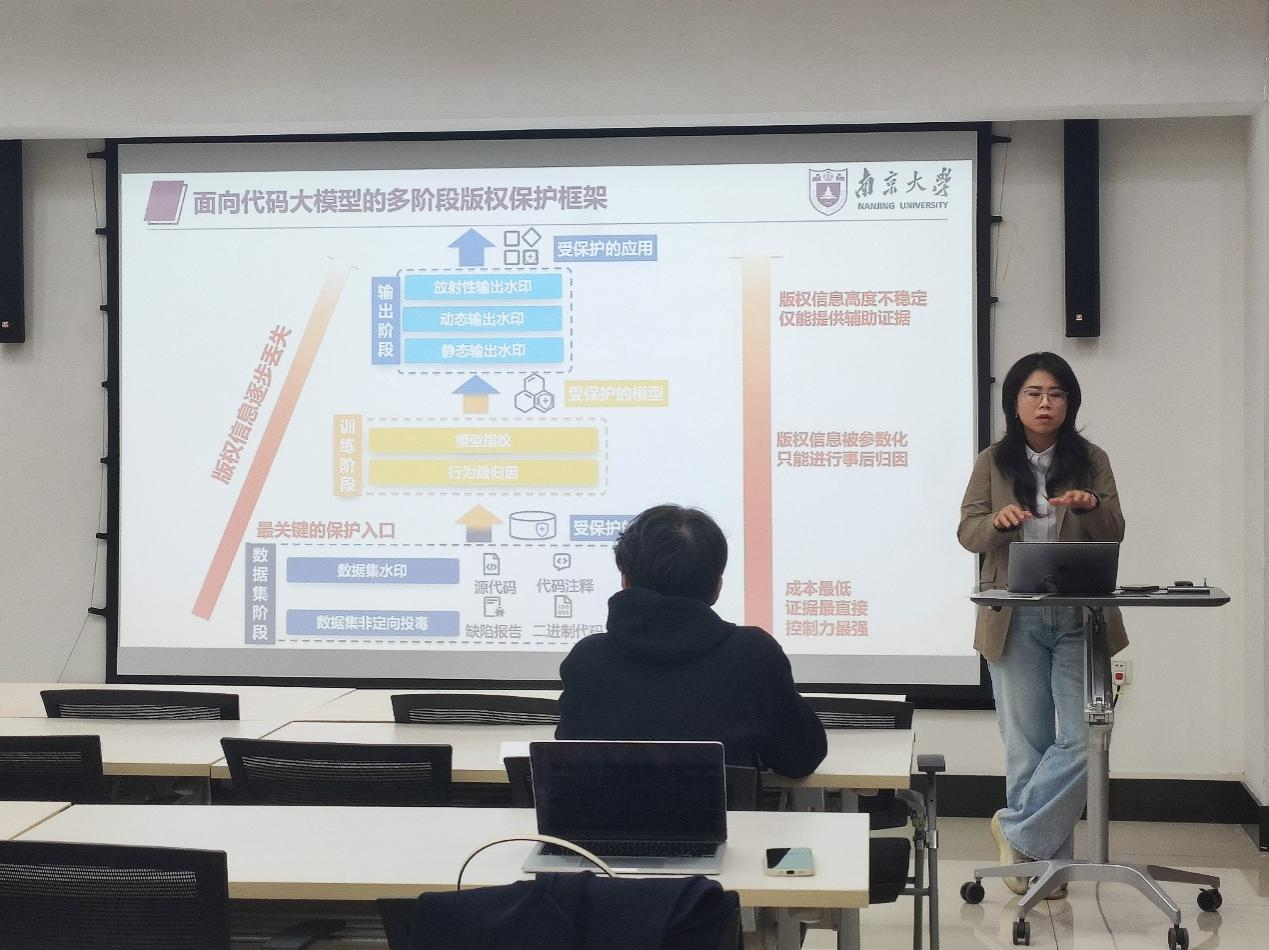
肖媛同学分享了其题为《面向代码大模型的数据集水印方法研究》的研究成果。随着代码大模型在代码生成与补全等任务中的广泛应用,大规模代码数据集已从工程资源演变为支撑模型能力的核心资产。然而,主流数据集多经自动化抓取、清洗与聚合构建,来源复杂,训练阶段的版权归属与使用边界难以界定和验证。传统基于许可证与法律文本的保护机制仅面向代码使用环节,对模型训练缺乏可执行的技术约束。报告聚焦代码大模型的数据集水印与版权保护,从软件工程视角系统梳理其设计动机、基本范式与核心挑战,重点探讨在不破坏代码语义正确性与工程可用性的前提下,如何嵌入可验证、隐蔽且能在训练阶段发挥作用的水印信息,并分析相关方法在模型训练及下游代码智能任务中的作用与局限,进而揭示数据集水印在AI时代代码资产溯源与治理中的潜在价值。

尹一鸣同学进行分享
尹一鸣同学报告了其题为《模型放置和自动并行加速多模态大模型训练》的研究工作。当前多模态大模型的发展从模型架构(如VLM、VALM)到训练策略(多阶段)尚未收敛至单一范式,负载差异与组件异构导致固定并行策略难以匹配动态训练需求,显存瓶颈与计算气泡问题突出。针对这一问题,该研究设计并实现了一套可自适应异构负载的训练加速系统:针对张量并行中通信气泡占比高、难以与计算重叠的问题,利用不同微批次间模态编码器与大语言基座计算-通信解耦的特性,交错执行各模块,实现跨批次细粒度计算通信重叠;针对传统流水线调度因激活显存不均造成的瓶颈,提出静态反向流水线调度,均衡显存压力,并为计算与通信重叠提供调度窗口。在此基础上,系统通过自动化搜索机制,依据模型结构与训练配置在线生成近似最优的模型放置与并行策略,有效提升多模态大模型训练效率。

在高翠芸教授的主持下,论坛现场学术氛围浓厚,师生提问踊跃,与两位报告人就数据集水印鲁棒性及多模态并行策略细节展开深入交流。通过本次论坛,参会的老师与同学们进一步了解了代码大模型数据治理与多模态高效训练的最新进展,激发了对相关领域的兴趣与思考。
演讲嘉宾:
肖媛,南京大学软件学院博士研究生。主要研究方向为代码大模型(Code LLMs)的安全与可信性,聚焦代码数据集与模型层面的水印、指纹及版权保护问题,从软件工程与软件供应链视角探索 AI 时代代码资产的溯源与治理机制。她的研究工作围绕代码数据集构建、模型训练及下游代码智能任务中的安全与鲁棒性问题展开,相关成果发表于 FSE、ISSTA、CVPR 等国际会议。其研究旨在为代码大模型在实际软件工程场景中的安全、合规与可控使用提供技术支撑。
尹一鸣,香港科技大学(广州)数据科学与分析学域二年级博士生,研究兴趣包括大模型分布式训练和推理系统,目前聚焦于多模态大模型的训练加速。



